- December 18, 2022
- Posted by: admin
- Category: BitCoin, Blockchain, Cryptocurrency, Investments
Beyond cryptocurrency tokens, the blockchain also enables analysts to get a clearer picture of practically any GameFi project, NFT, marketplace, or DeFi protocol, thanks to Footprint.
At Footprint, we’ve created a methodology that compiles and meaningfully aggregates the raw blockchain data. And this applies to programming integrations.
1 . Ways to work with the blockchain data
Let’s first talk about programming integration methods. There are a few different ways to work with blockchain data, and your chosen approach will depend on your specific needs and goals. Here is a quick overview:
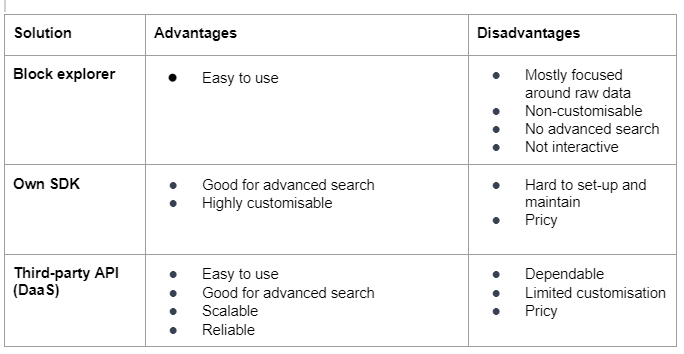
1.1 Blockchain explorers
A blockchain explorer is a website or tool that allows you to view the data stored on a blockchain. This can be a quick and easy way to access information about specific transactions, blocks, and other data on the blockchain.
Blockchain explorers can be a useful tool for accessing and viewing data stored on a blockchain, but they do have some limitations for software integrations. Here are a few examples of things that blockchain explorers may lack:
- Mainly focused on raw data. Blockchain explorers typically display raw data from the blockchain. That requires implementing the abstractions over the raw data, which can be tedious, especially for projects focused on delivery rather than on the technical details of certain blockchains.
- Customization options: Blockchain explorers are typically designed to be user-friendly and easy to use, which means they may not offer many customization options. This can make it difficult to tailor the explorer to your specific needs or preferences.
- Advanced search functionality: Blockchain explorers often have basic search functionality but may not support more advanced search features such as Boolean operators or regular expressions. This can make it difficult to search for specific information on the blockchain.
- Interactivity: Many blockchain explorers are essentially read-only tools.
While blockchain explorers can be a helpful way to access and view blockchain raw data, they do have some limitations that you should be aware of before deciding to implement your solution infrastructure based on them.
1.2 Own indexing solution
Setting up your own indexer to work with blockchain data can have several advantages and potential disadvantages. Here are a few examples of each:
Advantages:
- Customization: When you set up your indexer, you have complete control over how the data is indexed and accessed. This can allow you to tailor the indexer to your specific needs and preferences.
- Independence: By setting up your indexer, you are not relying on a third-party service to maintain and update the index. This can provide greater control and flexibility in your work with blockchain data.
- Improved security: When you set up your own indexer, you can implement your own security measures to protect the data and prevent unauthorized access.
Disadvantages:
- Complexity: Setting up your indexer can be a complex and time-consuming process, especially if you are new to working with blockchain technology. You will need to understand the underlying technology and be willing to invest the time and effort required to get the indexer up and running.
- Maintenance: Once you have set up your indexer, you will be responsible for maintaining and updating it. This can require ongoing technical expertise and resources, which can be a disadvantage if you do not have the necessary knowledge or support.
- Cost: Setting up your own indexer can be expensive, as you must purchase the hardware and software required to run the indexer and pay for any associated costs, such as electricity and bandwidth.
Overall, setting up your own indexer to work with blockchain data can provide greater control and customization, but it can also be a complex and expensive process. It’s important to consider the advantages and disadvantages carefully before deciding if this is the right approach.
1.3 Database as a service
Using a third-party indexer to work with blockchain data can have several advantages and potential disadvantages. Here are a few examples of each:
Advantages:
- Ease of use: Third-party indexers are typically designed to be easy to use, which means you can start working with the blockchain data quickly and without having to learn a lot of technical details or running your custom indexing solution (doesn’t matter whether it is self-developed or a ready-made SDK)
- Advanced search functionality: Many third-party indexers offer advanced search functionality, such as Boolean operators and regular expressions, making searching for specific information on the blockchain easier. These can have many actual implementations, but the indexed data is often added to a relational database, which implies full SQL support.
- Scalability: Third-party indexers are often designed to handle large volumes of data, which means they can be a good option if you need to search or access data from a large blockchain.
- Reliability: Third-party indexers are typically run by professional organizations with the resources and expertise to ensure the index is always up-to-date and accurate. Solutions are not always decentralized, as they are focused on processing huge amounts of data, but the vast majority are open source, which increases user confidence in the service.
Disadvantages:
- Dependency: Using a third-party indexer, you rely on that service to maintain and update the index. If the indexer experiences technical issues or goes offline, you may not be able to access the blockchain data.
- Limited customization: Third-party indexers are typically designed to be easy to use, which means they may not offer many customization options. This can make it difficult to tailor the indexer to your specific needs or preferences.
- Cost: Some third-party indexers may charge a fee for their services, which can be a disadvantage if you work on a tight budget.
In summary, using a third-party indexer to work with blockchain data can be a convenient and effective option, but limited and sometimes lack customization.
1.4 Summary
The goal of Footprint is primarily to lower the bar for entering analytics and working with web3 data. This approach is a balance between ease of use and flexibility. That is why one of our services is DaaS (Database as the service type). Before we take a closer look at the advantages of our service, we will also look at another implementation option for the indexer, namely a self-written solution or SDK.
In the next chapters, we will explore the core feature that read-only blockchain APIs should have. We will look at the problem from different angles and consider alternative solutions. Some of the most important features of blockchain APIs include the following:
- Ease of use and flexibility
- Scalability
- Compatibility
Ease of use and flexibility are two important features of blockchain APIs. A blockchain API that is easy to use will make it easier for developers to start building blockchain-based applications, allowing them to quickly prototype and test their ideas without spending a lot of time learning how to use the API.
Flexibility, on the other hand, refers to the ability of a blockchain API to support a wide range of use cases and applications. A flexible blockchain API will allow developers to access different parts of the blockchain and build applications that interact with different types of smart contracts and other blockchain-based assets. This can be especially important for developers looking to build applications that can be used in various industries and contexts.
Overall, having a blockchain API that is both easy to use and flexible can make it easier for developers to build innovative and useful applications that can take advantage of blockchain technology’s unique features and capabilities.
1.5 Footprint Analytics
Ease of use and flexibility is ensured by our data organization, which affects all aspects of interactions with the Footprint ecosystem. Footprint has an API built on top of this data model that allows users to build full-fledged data pipelines for data analysis and machine learning applications. We call it a Data API. We are simultaneously supporting two types of API and two sub-types within one of them to cover most of the cases: Rest API and SQL API.
REST API allows us to quickly integrate an application since each endpoint is a pre-built, hard-coded script that we have identified as one of the most popular. All endpoints come with easy-to-use tools for filtering, sorting, and pagination.
Thanks to the SQL API’s more adaptable interface, you can obtain this for more specific cases. One benefit of using the same SQL queries in both the web application and the API is that it can simplify development and maintenance. By using the same queries in both interfaces, developers can avoid the need to write and maintain separate sets of queries for the web application and the API. This can save time and effort and reduce the risk of errors or inconsistencies between the two interfaces.

Additionally, using the same SQL queries in both the web application and the API can make it easier for developers to create a seamless user experience. By using the same queries, developers can ensure that the data accessed and manipulated by the web application and the API is consistent, allowing users to switch between the two interfaces without encountering any inconsistencies or disruptions.
1.6 Other platforms
Many alternative analytics solutions allow the user to analyze different networks according to various levels of requirements. However, for the most part, alternative solutions tend to go to extremes, implementing either a very flexible product that requires knowledge of query languages or even programming languages or a very simple interface with prepared scripts and, accordingly, low flexibility.
Solutions like Moralis and Quicknode only have a REST API interface. Even though there are many endpoints, it still limits the developer in the flexibility of the data returned.
Dune has recently introduced its API. This asynchronous solution implies the preliminary existence of a query on the platform under a certain id (dune.com/query/{{query id}}), by which it is possible to execute queries in the form of SQL. The key limitation of this solution is the need to pre-modify the SQL on the platform so that the updated query is subsequently executed.
Chainbase releases SQL API in the same way as Footprint. Still, unlike Footprint, Chainbase does not have such sophisticated ETL, so SQL queries can only be executed for raw transactions.
2. Scalability
Blockchain APIs should be able to handle large volumes of data and transactions, allowing developers to build applications that can be used by many users simultaneously.
2.1 Footprint Analytics
2.1.1 Modern open data stack
The Footprint team has made several architectural upgrades since its launch in August 2021, thanks to its strong ability to explore and iterate on technology. In less than a year and a half, the team has been able to implement these changes successfully. This is a testament to the team’s skill and expertise in technology and data science.
Through experimentation, Footprint iteratively made three global architectural updates, ultimately arriving at an architecture that meets the requirements of the platform’s various use cases. More information on the evolution of the implementation can be found in the next article:
2.1.2 Sync and async executions
Within Footprint, there are two modes for executing queries to the SQL API – synchronous and asynchronous. API calls to the synchronous endpoint imply the SQL query will be executed by the Footprint servers as soon as an HTTP request is received from the application, thereby maintaining the connection. This makes sense when using lightweight requests, as in this case, the application does not have to wait long for execution. The details can be found on the following page:
https://docs.footprint.network/reference/post_native
For heavy requests, it is recommended to use an asynchronous request. Unlike a synchronous one, the client application does not have to maintain a connection with the server during execution. Instead, it can get the request-id immediately, according to which, after some time, separately get the execution results. As part of the asynchronous API, two-step should be covered to fetch the data – the following endpoint will be used to send an “order” for SQL execution:
https://docs.footprint.network/reference/post_native-async
The second step is to send a request to receive results by the identifier obtained when accessing the previous endpoint. The endpoint for this second step is described on the following page:
https://docs.footprint.network/reference/get_native-execution-id-results
2.2 Other solutions
DuneV2 changes the whole database architecture. Dune is now transitioning away from a PostgreSQL database to an Instance of [[Apache Spark]] hosted on [[Databricks]]. Only asynchronous API.
3. Compatibility
Blockchain APIs should be compatible with a wide range of programming languages and development environments so that developers can use the tools and frameworks they are most familiar with.
REST is easier to integrate since each programming language has many libraries that provide comfortable work with this type of API. However, in the end, both SQL APIs and REST work over HTTP, so the development experience is almost identical regarding sending a request by default.
4. Summary
As we have analyzed, in most cases, it is enough for an application to use ready-made DaaS solutions for the reason that they can return abstractions (not just raw data) and save a lot of time and money, as they ultimately allow teams to focus not on infrastructure but on the value of the product. Going through various solutions in the DaaS market,
Footprint seems to be the most optimal to integrate, as it has the most flexible model for generating requests while being both easy to use and also having the modern open-source data stack under the hood, which ensures uninterrupted and, most importantly, fast execution of the most complex requests.
The post How to choose a data provider for your web3 project? appeared first on CryptoSlate.























